This old version of Proteopedia is provided for student assignments while the new version is undergoing repairs. Content and edits done in this old version of Proteopedia after March 1, 2026 will eventually be lost when it is retired in about June of 2026.
Apply for new accounts at the new Proteopedia. Your logins will work in both the old and new versions.
1ywu
From Proteopedia
(Difference between revisions)
| Line 1: | Line 1: | ||
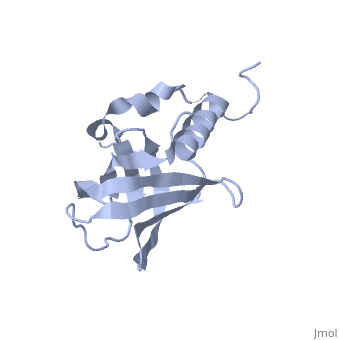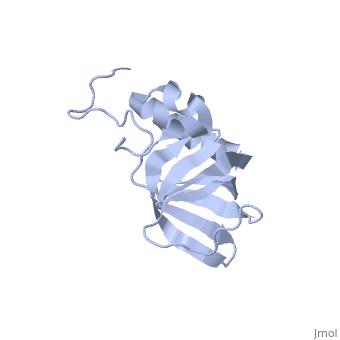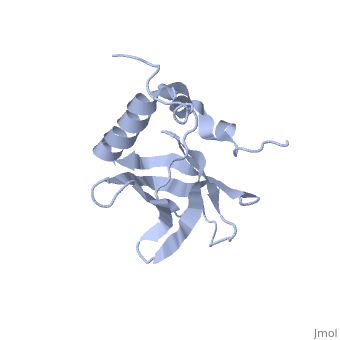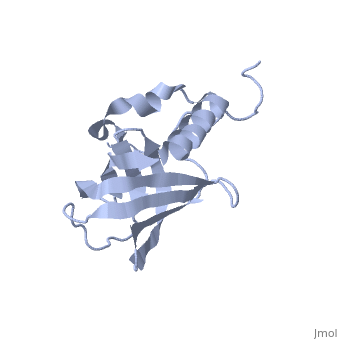
==Solution NMR structure of Pseudomonas Aeruginosa protein PA4608. Northeast Structural Genomics target PaT7== | ==Solution NMR structure of Pseudomonas Aeruginosa protein PA4608. Northeast Structural Genomics target PaT7== | ||
| - | <StructureSection load='1ywu' size='340' side='right'caption='[[1ywu | + | <StructureSection load='1ywu' size='340' side='right'caption='[[1ywu]]' scene=''> |
== Structural highlights == | == Structural highlights == | ||
| - | <table><tr><td colspan='2'>[[1ywu]] is a 1 chain structure with sequence from [ | + | <table><tr><td colspan='2'>[[1ywu]] is a 1 chain structure with sequence from [https://en.wikipedia.org/wiki/Pseudomonas_aeruginosa_PAO1 Pseudomonas aeruginosa PAO1]. Full experimental information is available from [http://oca.weizmann.ac.il/oca-bin/ocashort?id=1YWU OCA]. For a <b>guided tour on the structure components</b> use [https://proteopedia.org/fgij/fg.htm?mol=1YWU FirstGlance]. <br> |
| - | </td></tr><tr id=' | + | </td></tr><tr id='method'><td class="sblockLbl"><b>[[Empirical_models|Method:]]</b></td><td class="sblockDat" id="methodDat">Solution NMR</td></tr> |
| - | <tr id='resources'><td class="sblockLbl"><b>Resources:</b></td><td class="sblockDat"><span class='plainlinks'>[ | + | <tr id='resources'><td class="sblockLbl"><b>Resources:</b></td><td class="sblockDat"><span class='plainlinks'>[https://proteopedia.org/fgij/fg.htm?mol=1ywu FirstGlance], [http://oca.weizmann.ac.il/oca-bin/ocaids?id=1ywu OCA], [https://pdbe.org/1ywu PDBe], [https://www.rcsb.org/pdb/explore.do?structureId=1ywu RCSB], [https://www.ebi.ac.uk/pdbsum/1ywu PDBsum], [https://prosat.h-its.org/prosat/prosatexe?pdbcode=1ywu ProSAT], [https://www.topsan.org/Proteins/NESGC/1ywu TOPSAN]</span></td></tr> |
</table> | </table> | ||
== Function == | == Function == | ||
| - | [ | + | [https://www.uniprot.org/uniprot/CDGBP_PSEAE CDGBP_PSEAE] Binds the second messenger bis-(3'-5') cyclic dimeric guanosine monophosphate (c-di-GMP). Can bind two c-di-GMP molecules per monomer. May play a role in bacterial second-messenger regulated processes. Binding to c-di-GMP induces a conformational change of the C- and N-termini resulting in the exposure of a highly negative surface on one side of the protein to a possible effector protein.<ref>PMID:17096419</ref> <ref>PMID:21280119</ref> <ref>PMID:21310957</ref> |
== Evolutionary Conservation == | == Evolutionary Conservation == | ||
[[Image:Consurf_key_small.gif|200px|right]] | [[Image:Consurf_key_small.gif|200px|right]] | ||
| Line 19: | Line 19: | ||
</jmol>, as determined by [http://consurfdb.tau.ac.il/ ConSurfDB]. You may read the [[Conservation%2C_Evolutionary|explanation]] of the method and the full data available from [http://bental.tau.ac.il/new_ConSurfDB/main_output.php?pdb_ID=1ywu ConSurf]. | </jmol>, as determined by [http://consurfdb.tau.ac.il/ ConSurfDB]. You may read the [[Conservation%2C_Evolutionary|explanation]] of the method and the full data available from [http://bental.tau.ac.il/new_ConSurfDB/main_output.php?pdb_ID=1ywu ConSurf]. | ||
<div style="clear:both"></div> | <div style="clear:both"></div> | ||
| - | <div style="background-color:#fffaf0;"> | ||
| - | == Publication Abstract from PubMed == | ||
| - | PA4608 is a 125 residue protein from Pseudomonas aeruginosa with a recent identification as a PilZ domain and putative bis-(3'-5')-cyclic dimeric guanosine monophosphate (c-di-GMP) adaptor protein that plays a role in bacterial second-messenger regulated processes. The nuclear magnetic resonance (NMR) structure of PA4608 has been determined and c-di-GMP binding has been confirmed by NMR titration studies. The monomeric core structure of PA4608 contains a six-stranded anti-parallel beta barrel flanked by three helices. Conserved surface residues among PA4608 homologs suggest the c-di-GMP binding site is at one end of the barrel and includes residues in the helices as well as in the unstructured N-terminus. Chemical shift changes in PA4608 resonances upon titration with c-di-GMP confirm binding. This evidence supports the hypothesis that proteins containing PilZ domains are the long-sought c-di-GMP adaptor proteins. | ||
| - | |||
| - | NMR structure and binding studies confirm that PA4608 from Pseudomonas aeruginosa is a PilZ domain and a c-di-GMP binding protein.,Ramelot TA, Yee A, Cort JR, Semesi A, Arrowsmith CH, Kennedy MA Proteins. 2007 Feb 1;66(2):266-71. PMID:17096419<ref>PMID:17096419</ref> | ||
| - | |||
| - | From MEDLINE®/PubMed®, a database of the U.S. National Library of Medicine.<br> | ||
| - | </div> | ||
| - | <div class="pdbe-citations 1ywu" style="background-color:#fffaf0;"></div> | ||
| - | |||
| - | ==See Also== | ||
| - | *[[PilZ domain|PilZ domain]] | ||
| - | *[[Protein PA4608|Protein PA4608]] | ||
== References == | == References == | ||
<references/> | <references/> | ||
| Line 37: | Line 24: | ||
</StructureSection> | </StructureSection> | ||
[[Category: Large Structures]] | [[Category: Large Structures]] | ||
| - | [[Category: | + | [[Category: Pseudomonas aeruginosa PAO1]] |
| - | [[Category: Arrowsmith | + | [[Category: Arrowsmith CH]] |
| - | [[Category: Cort | + | [[Category: Cort JR]] |
| - | [[Category: Kennedy | + | [[Category: Kennedy MA]] |
| - | + | [[Category: Ramelot TA]] | |
| - | [[Category: Ramelot | + | [[Category: Semesi A]] |
| - | [[Category: Semesi | + | [[Category: Yee AA]] |
| - | [[Category: Yee | + | |
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
| - | + | ||
Current revision
Solution NMR structure of Pseudomonas Aeruginosa protein PA4608. Northeast Structural Genomics target PaT7
| |||||||||||