This old version of Proteopedia is provided for student assignments while the new version is undergoing repairs. Content and edits done in this old version of Proteopedia after March 1, 2026 will eventually be lost when it is retired in about June of 2026.
Apply for new accounts at the new Proteopedia. Your logins will work in both the old and new versions.
DOPA decarboxylase
From Proteopedia
| Line 34: | Line 34: | ||
====Quaternary Structure==== | ====Quaternary Structure==== | ||
The level of protein structure exists solely in multisubunit complexes. DOPA decarboxylase is a homodimeric enzyme with the active site located near the monomer-monomer interface, thus highlighting the importance of this level of protein structure to the enzymes function. Furthermore, since the N-terminal domain of one monomer packs on top of the other monomer, resulting in an extended dimer interface, this level of tertiary structure is most likely stable only in the dimeric form of the enzyme. | The level of protein structure exists solely in multisubunit complexes. DOPA decarboxylase is a homodimeric enzyme with the active site located near the monomer-monomer interface, thus highlighting the importance of this level of protein structure to the enzymes function. Furthermore, since the N-terminal domain of one monomer packs on top of the other monomer, resulting in an extended dimer interface, this level of tertiary structure is most likely stable only in the dimeric form of the enzyme. | ||
| - | + | ||
====Helix Capping==== | ====Helix Capping==== | ||
The α helix is characterized by main chain hydrogen bonds between the C=O of residue n and the NH of residue n+4. All residues in the helix participate in this type of hydrogen bonding except the first NH groups and the last C=O groups at the ends of the helix. Helix-capping motifs are specific hydrogen bonding and hydrophobic interactions found at the ends of helices. Seven distinct capping motifs have been identified; three at the N-terminus and four at the C-terminus. Shown below is the '''capping-box''' motif found at the end of the helix composed of residues 147-171. Here, Ncap is Ser-147. The hydroxyl oxygen of Ser-147 forms a standard Ncap hydrogen bond with the amide of N3 (Glu-150), and the side chain carbonyl oxygen of Glu-150 forms a hydrogen bond with the amide of Ser-147. This form of special capping satisfies two of the four non hydrogen-bonded helix N-terminal amides. The side-chain capping apparent here is typical at the N-terminus. According to Aurora and Rose, this would be termed a motif Ib, N`-> N4 motif. Thus, the important hydrophobic interaction occurs between N` (Gly-146) and N4 (Ala-151). | The α helix is characterized by main chain hydrogen bonds between the C=O of residue n and the NH of residue n+4. All residues in the helix participate in this type of hydrogen bonding except the first NH groups and the last C=O groups at the ends of the helix. Helix-capping motifs are specific hydrogen bonding and hydrophobic interactions found at the ends of helices. Seven distinct capping motifs have been identified; three at the N-terminus and four at the C-terminus. Shown below is the '''capping-box''' motif found at the end of the helix composed of residues 147-171. Here, Ncap is Ser-147. The hydroxyl oxygen of Ser-147 forms a standard Ncap hydrogen bond with the amide of N3 (Glu-150), and the side chain carbonyl oxygen of Glu-150 forms a hydrogen bond with the amide of Ser-147. This form of special capping satisfies two of the four non hydrogen-bonded helix N-terminal amides. The side-chain capping apparent here is typical at the N-terminus. According to Aurora and Rose, this would be termed a motif Ib, N`-> N4 motif. Thus, the important hydrophobic interaction occurs between N` (Gly-146) and N4 (Ala-151). | ||
Revision as of 00:39, 27 June 2011
Contents |
Introduction
| |||||||||
| 1js3, resolution 2.25Å () | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Ligands: | , , | ||||||||
| Activity: | Aromatic-L-amino-acid decarboxylase, with EC number 4.1.1.28 | ||||||||
| Related: | 1js6 | ||||||||
| |||||||||
| |||||||||
| Resources: | FirstGlance, OCA, RCSB, PDBsum | ||||||||
| Coordinates: | save as pdb, mmCIF, xml | ||||||||
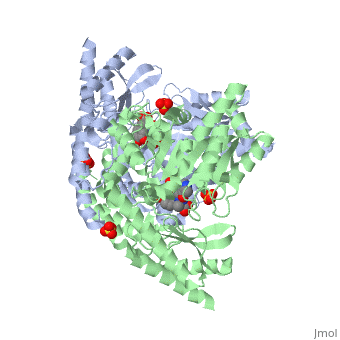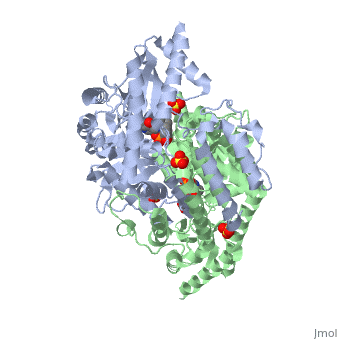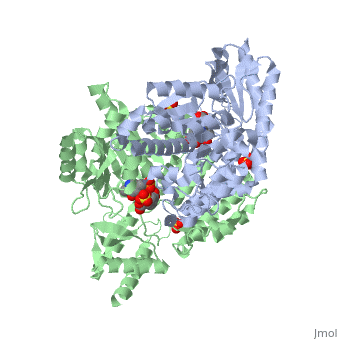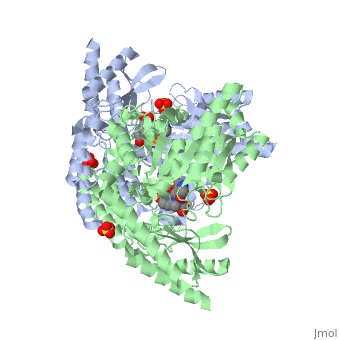


DOPA decarboxylase is responsible for the synthesis of dopamine and serotonin from L-DOPA and L-5-hydroxytryptophan, respectively. Due to its role in neurotransmitter synthesis, DOPA decarboxylase has been implicated in Parkinson's disease, a disease thought to be the result of the degeneration of dopamine-producing cells in the brain. Currently, treatment for the disease is aimed at DOPA decarboxylase inhibition. Since dopamine cannot cross the blood-brain barrier, it cannot be used to directly treat Parkinson's disease. Thus, exogenously administered L-DOPA is the primary treatment for patients suffering from this neurodegenerative disease. Unfortunately, DOPA decarboxylase rapidly converts L-DOPA to dopamine in the blood stream, with only a small percentage reaching the brain. By inhibiting the enzyme, greater amounts of exogenously administered L-DOPA can reach the brain, where it can then be converted to dopamine. [2]
PLP-Dependent Enzymes
Overview
Pyridoxal-5'-phosphate (PLP), the biologically active phosphorylated derivative of vitamin B6, is a versatile and abundant cofactor to a variety of enzymes in all organisms. Almost all PLP-dependet enzymes function in pathways associated with amino compounds, primarily amino acid metabolism. These enzymes carry out many types of reactions, including transaminations, decarboxylations', racemizations, and deaminations (amongst others). PLP is considered to be the most versatile cofactor, thus imparting a wide range of functions on PLP-dependent enzymes. This versatility stems from the fact that PLP can covalently bind the substrate and then act as an electrophilic catalyst. And although these enzymes have wide range of function, there exist only five structural classes: the aspartate amino transferase family, the tryptophan synthase β family, the alanine racemase family, the D-amino acid family, and the glycogen phosphorylase family. [3] [1]
The Aspartate Aminotransferase Family
This family of PLP-dependent enzymes is also referred to as fold-type I, with aspartate aminotransferase serving as the prototype. It is the most common structure of the five classes of PLP-dependent enzymes. This fold it is found in a variety of aminotransferases and decarboxylases, amongst them DOPA decarboxylase. PLP-dependent enzymes belonging to this family are catalytically active as homodimers and share a common, well-characterized structure, despite low-sequence identity. Each subunit has a large domain and a small domain. The central feature of the large domain is a seven-stranded β sheet. The small domain has either a three or four-stranded β sheet that is surrounded by α helices on one side. The cofactor PLP is covalently attached to a lysine residue in the large domain and is anchored in a way that allows the aromatic ring of PLP to pack against neighboring β strands. The active site is located in a cleft between the two domains at the interface between the two subunits. Thus, enzymes of fold-type I have residues from both domains and both subunits involved in PLP-binding.



DOPA Decarboxylase
Primary Structure
The amino acid sequence of a proteins polypeptide chain is referred to as its primary structure. Each polypeptide chain of DOPA decarboxylase is composed of 486 amino acids that ultimately encode the three-dimensional structure of the protein.
Secondary Structure
The formation of secondary structural elements (like α helices and β sheets) arise in response to the hydrophobic effect and the need to neutralize main-chain polar groups by hydrogen bonding. Each polypeptide chain of DOPA decarboxylase is composed of a seven-stranded mixed , a four-stranded anti-parallel , several , and other, lesser known, secondary structural elements (like loops and the extended strand). Another common secondary structure is the β-turn, or reverse turn. Depicted below is an example of a Type 1 β-turn of DOPA decarboxylase.
This β-turn is comprised of residues Leu-440, Arg-441, Gly-442, and Gln-443. The distance between Cαi and Cαi+3 is 5.1Å, within the acceptable limit of 7Å. As in most β-turns, there is a hydrogen bond between the C=O of Leu-440 and the NH of Gln-443. The phi and psi angles of residues i+1 (Arg-441) and i+2 (Gly-442) are indicated in the diagram.
Tertiary Structure
This level of protein structure refers to the overall three-dimensional shape the polypeptide chain creates. Domains are the fundamental units that generate the tertiary structure, and DOPA decarboxylase is composed of three distinct domains.

The contains the PLP-binding site, and consists of a seven-stranded mixed β sheet that is surrounded by eight α helices, resulting in a typical α/β fold, the most regular and common of the protein structures (recall that α helices and β strands typically alternate in this fold, generating an outer layer of α helices and an inner layer of β sheets). This particular fold falls into the class of open twisted parallel or mixed β sheet with α helices on both sides of the sheet. The small is comprised of a four-stranded anti-parallel β sheet that has three α helices packed against the face opposite to the large domain. Although the aforementioned domains exist in all members of this family of PLP-dependent enzymes, including bacterial ornithine decarboxylase (OrnDC) and dialkylglycine decarboxylase (DGD), the is unique to DOPA decarboxylase, and is a representative case of domain swapping. This domain is composed of two parallel helices linked by an extended strand, which essentially lies like a flap over the second subunit. As well, residues from the N-terminal domain and the small domain form a short
Quaternary Structure
The level of protein structure exists solely in multisubunit complexes. DOPA decarboxylase is a homodimeric enzyme with the active site located near the monomer-monomer interface, thus highlighting the importance of this level of protein structure to the enzymes function. Furthermore, since the N-terminal domain of one monomer packs on top of the other monomer, resulting in an extended dimer interface, this level of tertiary structure is most likely stable only in the dimeric form of the enzyme.
Helix Capping
The α helix is characterized by main chain hydrogen bonds between the C=O of residue n and the NH of residue n+4. All residues in the helix participate in this type of hydrogen bonding except the first NH groups and the last C=O groups at the ends of the helix. Helix-capping motifs are specific hydrogen bonding and hydrophobic interactions found at the ends of helices. Seven distinct capping motifs have been identified; three at the N-terminus and four at the C-terminus. Shown below is the capping-box motif found at the end of the helix composed of residues 147-171. Here, Ncap is Ser-147. The hydroxyl oxygen of Ser-147 forms a standard Ncap hydrogen bond with the amide of N3 (Glu-150), and the side chain carbonyl oxygen of Glu-150 forms a hydrogen bond with the amide of Ser-147. This form of special capping satisfies two of the four non hydrogen-bonded helix N-terminal amides. The side-chain capping apparent here is typical at the N-terminus. According to Aurora and Rose, this would be termed a motif Ib, N`-> N4 motif. Thus, the important hydrophobic interaction occurs between N` (Gly-146) and N4 (Ala-151).
Proteopedia Page Contributors and Editors (what is this?)
Brittany Todd, David Canner, Michal Harel, Alexander Berchansky, Brian Hernandez

{kind=link}
{kind=link}