Sandbox Reserved 321
From Proteopedia
| This Sandbox is Reserved from January 10, 2010, through April 10, 2011 for use in BCMB 307-Proteins course taught by Andrea Gorrell at the University of Northern British Columbia, Prince George, BC, Canada. |
To get started:
More help: Help:Editing |
InhA
by Kelly Hrywkiw
| |||||||||
| 2h9i, resolution 2.20Å () | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Ligands: | |||||||||
| Gene: | inhA (Mycobacterium tuberculosis) | ||||||||
| Activity: | [acyl-carrier-protein_reductase_(NADH) Enoyl-[acyl-carrier-protein] reductase (NADH)], with EC number 1.3.1.9 | ||||||||
| Related: | 1zid | ||||||||
| |||||||||
| |||||||||
| Resources: | FirstGlance, OCA, PDBsum, RCSB | ||||||||
| Coordinates: | save as pdb, mmCIF, xml | ||||||||
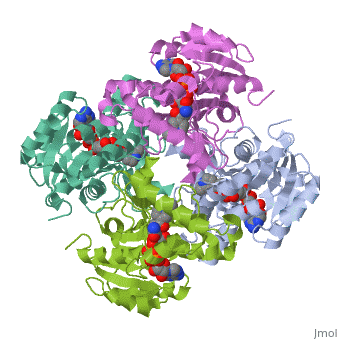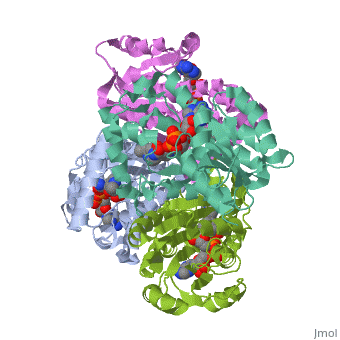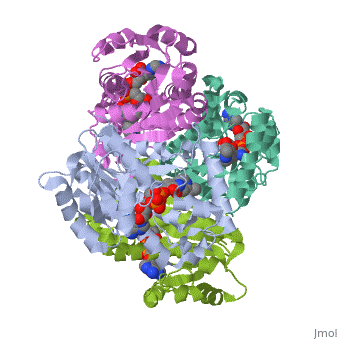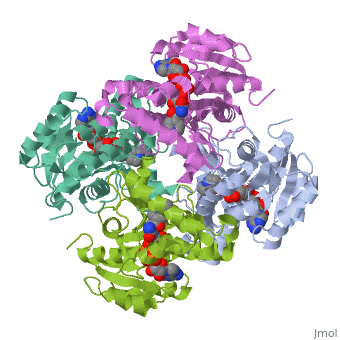

Contents |
Introduction
The enzyme inhA is coded from the inhA gene that is simillar in sequence to the Salmonella typhimuriumgene which plays a role in fatty acid biosynthesis [1]. Inha is an NADH dependent trans enoyl-acyl ACP carrier protein that plays a role in the sysnthesis of Mycolic Acid, and is part of a short-chain dehydrogenase/reductase family [2][3]. Mycolic acids are long chain fatty acids that are essential in cell wall formation of the human pathogen Mycobacterium tuberculosisas well as other mycobateria such as Mycobacterium leprae[4]. Inha has been propsed as the target of the thioamide drugs, ethionamide (ETH) and isoniazid (INH), which have been used in treatment of mycobacterial infections [3].
Structure of inhA
The inhA enzyme of M. tuberculosis is a homotetramer composed of a repeating subunit comprised of a single domain with a Rossmann Fold in the core that provides a NADH binding site[5]. The single domain can be broken down into two substructures that are connected by short peptide loop[1][5].
|
Substructure 1 of inhA
consists of 6 parallel β strands and 4 α helices interwoven together to form a core α/β structure that contains the n-terminal domain[1]. The first substructure can be further broken down into two sections, the consisting of two β strands and two short α helicies [1]. The first section is connected to the by a β strand that crosses over the two domains, and leads into the second section initiating at the third α helix [1](A-3) is connected by a long loop to a 14 residue β strand that then leads into the fourth α helix [1]. A-4 then leads into a fifth strand β , followed by a 25 residue α helix , and into the final strand β [1].
Substructure 2 of inhA
contains the c-terminal region of the molecule and consists of a small β strand , and two α helicies which are conected by a short five residue loop[1]. The C-terminal domain consits of two other α helicies [1].
Function
InhA plays a key role in the synthesis of fatty acids, particularly in M. tuberculosis which has type one fatty acid synthesis (FASI) and type two fatty acid synthesis (FASII) which together funtion in the synthesis of mycolic acids.[6]. The final step in FASII is compleated by InhA which reduces 2-trans-enoyl-ACP's with chain lengths over twelve carbons [6]
Role in the Mycolic Acid Pathway


{kind=link}